The Transformer model has revolutionized natural language processing and has been widely used for response generation tasks. However, the quality of generated responses can sometimes be affected by irrelevant or incoherent responses. Transformer response optimizationis a technique used to improve the quality of generated responses by optimizing the decoding process of the Transformer model. In this article, we will explore some of the techniques used for Transformer response optimization.
What Is Transformer Response Optimization?

Transformer Response Optimization is a technique used to improve the quality of generated responses in the Transformer model for natural language processing. The optimization involves refining the decoding process of the Transformer model to generate more coherent and relevant responses.
Techniques such as beam search, sampling, top-k sampling, nucleus sampling, and length penalty are commonly used for optimizing the response generation process in the Transformer model. By further developing and refining these techniques, we can continue to improve the performance of the Transformer model and enhance the overall user experiencein natural language processing applications.
Reasons To Start Thinking About TRO
Here are some reasons why you might want to start thinking about Transformer Response Optimization (TRO):
- Improved Chatbot Performance- If you're building a chatbot, TRO can help improve the quality and relevance of the responses generated by the bot, leading to a better user experience.
- Better Language Translation- TRO can help improve the accuracy and fluency of machine translation systems by generating more coherent and relevant translations.
- Enhanced Content Creation- TRO can be used to generate more diverse and engaging contentfor social media, marketing, and other content creation tasks.
- More Accurate Summarization - TRO can help improve the accuracy and relevance of text summarization systems by generating more informative and focused summaries.
- Increased Efficiency- TRO can help reduce the number of iterations needed to generate a high-quality response, which can save time and resources.
TRO can help improve the performance and quality of a wide range of natural language processing tasks, making it an important area of research and development for the future of AI and machine learning.
Disadvantages Of Transformer Response Optimization
- Increased Complexity - Transformer response optimization can be complex and require additional computational resources and expertise.
- Overfitting- If not properly implemented, Transformer response optimization techniques can result in overfitting, where the model is optimized too closely to the training data and fails to generalize well to new data.
- Difficulty in Interpretation- Transformer response optimization can make it difficult to interpret the underlying decision-making process of the model, making it harder to identify errors or biases.
- Increased Cost- Transformer response optimization can require additional computational resources, which can increase the cost of running the model.
- Reduced Speed- Transformer response optimization can increase the time required to generate a response, which can be a problem in real-time applications such as chatbots or customer support systems.
While Transformer response optimization has many advantages, it's important to carefully consider the potential drawbacks and implement it in a way that balances performance, efficiency, and interpretability.
Techniques For Transformer Response Optimization
Beam Search
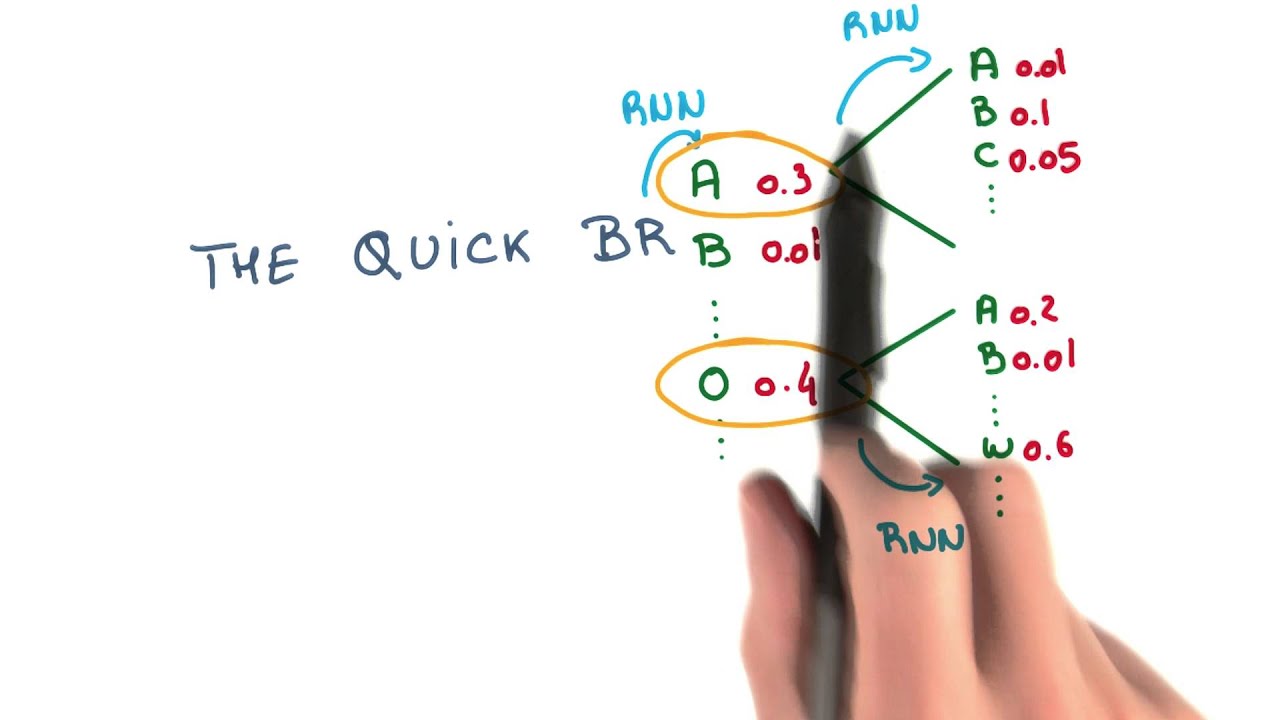
Beam Search
Beam Search is a widely used technique for response generation in the Transformer model. It is a deterministic algorithm that generates a set of possible responses and selects the most probable response based on a predefined scoring function.
In Beam Search, the algorithm maintains a list of the top k most probable next words at each decoding step. The list is updated based on the probability distribution over the vocabulary and the previous context. The size of the list is called the beam width, and it determines the number of possible responses generated at each decoding step.
At the end of the decoding process, the algorithm selects the response with the highest score based on the predefined scoring function. The scoring function can be based on the probability of the response or other factors such as length or relevance.
Beam Search is a simple and effective technique for response generation in the Transformer model. However, it can also generate suboptimal or redundant responses, especially when the beam width is small. To address this issue, various extensions of Beam Search, such as diverse Beam Search or length-normalized Beam Search, have been proposed to improve the quality of generated responses.
Sampling
Sampling is a technique used for response generation in the Transformer model. It generates responses by randomly selecting from the probability distribution over the vocabulary. The probability distribution is calculated based on the previous context and the learned model parameters. There are several different sampling techniques that can be used to generate responses, including:
- Greedy Sampling- Greedy Sampling selects the word with the highest probability at each decoding step. This technique is simple and efficient but may generate repetitive or incomplete responses.
- Top-k Sampling- Top-k Sampling selects the top k words with the highest probability at each decoding step and then randomly samples from this set. This technique can generate more diverse responses than Greedy Sampling.
- Nucleus Sampling- Nucleus Sampling selects the smallest set of words that account for a fixed probability mass, usually 0.9, and then randomly samples from this set. This technique can generate even more diverse and interesting responses than Top-k Sampling.
Sampling techniques can produce more creative and diverse responses than deterministic methods like Beam Search. However, they can also generate responses that are less coherent or relevant. To address this issue, techniques such as temperature scaling or fine-tuning the sampling distribution have been proposed to balance diversity and coherence.
Length Penalty
Length Penalty is a technique used to encourage the Transformer model to generate responses of a certain length. The length of the response can be an important factor in determining its quality and relevance. Without the Length Penalty, the Transformer model may generate responses that are either too short or too long.
The Length Penalty is usually applied as a penalty term to the scoring function that is used to select the best response. The penalty term is a function of the length of the response and the penalty coefficient. The penalty coefficient is a hyperparameter that determines the strength of the penalty term.
The penalty term discourages the model from generating responses that are too short or too long. If the length of the response is too short, the penalty term will reduce its score, making it less likely to be selected. If the length of the response is too long, the penalty term will also reduce its score, penalizing the model for generating unnecessary or redundant words.
Temperature Scaling
Temperature Scaling is a technique used to control the diversity of generated responses in the Transformer model. It involves adjusting the temperature parameter of the softmax function that generates the probability distribution over the vocabulary.
In the Transformer model, the probability distribution over the vocabulary is calculated using the softmax function, which maps the logit scores to a probability distribution. The softmax function uses the temperature parameter to control the shape of the distribution. A higher temperature value makes the distribution more uniform, while a lower temperature value makes the distribution more peaked.
By adjusting the temperature parameter, the Transformer model can generate responses that are more diverse or more conservative. A higher temperature value encourages the model to generate more diverse responses, while a lower temperature value encourages the model to generate more conservative and likely responses.
Temperature Scaling can be used in conjunction with other techniques, such as Beam Search or Sampling, to optimize the response generation process. For example, temperature-adjusted Sampling can generate a more diverse set of responses by increasing the temperature parameter during the sampling process.
Ensemble Methods

Machine Learning | Ensemble Methods
Ensemble Methods are a technique used to improve the quality and diversity of generated responses in the Transformer model. Ensemble Methods involve combining multiple Transformer models, each trained on different datasets or with different hyperparameters, to generate a more diverse set of responses.
The basic idea behind Ensemble Methods is that by combining multiple models, the resulting ensemble model can capture a broader range of knowledge and generate more diverse responses. Ensemble Methods can also help reduce the impact of overfitting and increase the robustness of the model.
There are several ways to implement Ensemble Methods in the Transformer model. One common approach is to use different subsets of the training data to train each model in the ensemble. Another approach is to use different hyperparameters, such as learning rate or batch size, to train each model.
Ensemble Methods can be combined with other techniques, such as Beam Search or Sampling, to further optimize the response generation process. For example, Ensemble Methods can be used with length-normalized Beam Search to generate a more diverse set of responses while still maintaining coherence and relevance.
People Also Ask
How Can Length Penalty Improve Response Generation In The Transformer Model?
Length penalty is a technique used to encourage the model to generate responses of a certain length. It is usually applied as a penalty term to the scoring function.
What Is Sampling In Transformer Response Optimization?
Sampling is a technique used for response generation in the Transformer model. It generates responses by randomly selecting from the probability distribution over the vocabulary.
How Can Beam Search Be Used For Response Optimization In The Transformer Model?
Beam search is a technique used for response generation in the Transformer model. It generates several possible responses and selects the most probable response based on a predefined scoring function.
Conclusion
Transformer response optimization is a crucial technique in natural language processing for improving the quality of generated responses. By further developing and refining these techniques, we can continue to improve the performance of the Transformer model and enhance the overall user experience in natural language processing applications.
With the rapid development of natural language processing, the future of Transformer response optimization is promising, and we can expect to see even more exciting advancements in this field.