Our ability to identify images is based on our ability to discern between different aspects of objects.For this reason, we are able to effortlessly distinguish between distinct objects since our brains were trained unknowingly to associate them with similar imagery.
We're not even aware of how we see the world around us.You won't have any trouble discriminating between distinct visual elements.Everything is handled automatically by our subconscious mind.
Unlike humans, computers see visuals as an array of numerical values and hunt for patterns in digital images, whether they're a still or a video or even live, in order to recognize and distinguish significant elements.
The way a computer analyzes an image is entirely distinct from how we do.Visuals can be analyzed and understood from a single image or several photos using computer vision techniques.
Computer vision can be used to accurately classify and filter millions of user-uploaded images in order to accurately identify people and cars on the road.

Deep Learning AI: How Image Recognition Works
What Is The Purpose Of Image Recognition?
An image or video can be recognized by a computer camera using a process known as image recognition.For example, it is a way to capture and analyze photographs.Computers employ artificially intelligent machine vision technology to recognize and detect images.The following is a common image recognition algorithm:
- Optical character resemblance
- Matching patterns and gradations
- Recognition of a face
- Matching the license plate is the goal.
- Identification of the setting
When it comes to digital photographs, the term "image recognition" refers to technologies that are able to recognize a variety of different factors in the images themselves.
Humans, like you and me, may be able to recognize various visuals, such as those of animals.When we see an image of a cat, we can tell it apart from an image of a horse in an instant.For a computer, though, it may not be that straightforward.
Pixels, or picture elements, are the numeric representations of the intensity or gray level of an image in a digital format.
As a result, the computer sees images as a collection of number values for each pixel, and it must recognize patterns and regularities in this numerical data in order to identify a particular image.

Object detection and image recognition are not the same thing.
When it comes to object detection, we look at an image to see what items are present, whereas image recognition is concerned with identifying those images and sorting them into distinct groups.
How Does Image Recognition Work?
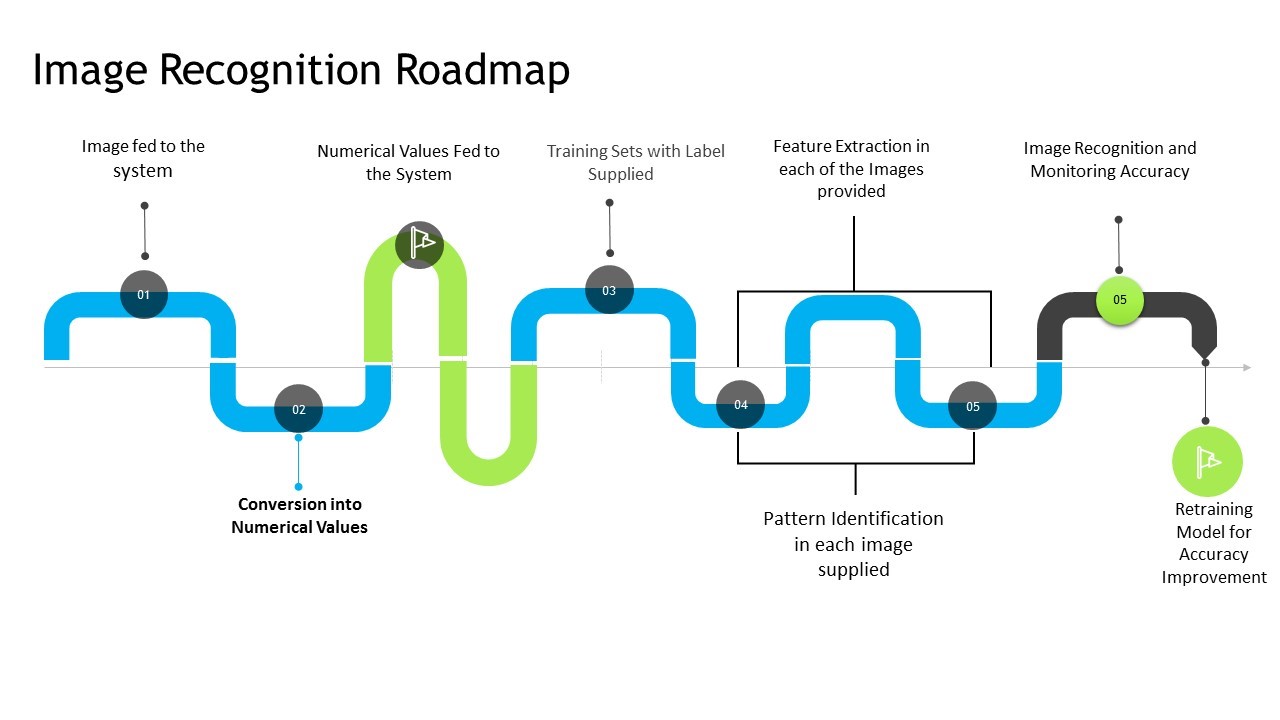
Numerical quantities are encoded in the digital image.The data associated with each pixel in the image is represented by these values.Using a matrix, the intensity of each pixel is averaged to provide a single value.
The intensity and location of each pixel in the image are used as input to the recognition algorithms.As part of the learning process, the systems use this information to identify a pattern or relationship in the images it receives in the future.
System performance is verified using test data after training is complete.
Continuous weights for neural networks are changed intermittently in order to increase the system's ability to distinguish images
These include SIFT (Scale-invariant Feature Transform) and SURF (Sped Up Robust Features), PCA (Principal Component Analysis) and LDA (Latent Dirichlet Allocation) (Linear Discriminant Analysis).
How Image Recognition Works
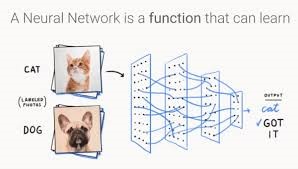
As previously said, picture recognition technology mimics mental processes.The human brain's unique structure allows us to learn to recognize objects swiftly and unconsciously.In technical jargon, our brain can subconsciously or autonomously generate neuron impulses.
Despite all technological advances, computers cannot recognize humans.For them, an image is a collection of pixels, each of which is described by a number value.Deep learning techniques are used to compare these data to threshold settings.Changing their settings affects network activity and how objects are identified.
Neural Network Structure
There are many different types of neural networks, and each one is better suited for a given task.Due to its unique working concept, convolutional neural networks (CNN) get the greatest results in deep learning image recognition.There are currently a number of different CNN architectures in use.To have a better idea of what's going on, let's take a look at a classic variant.
Input Layer Or Neural Network Gates
The input layer of most neural network CNNs serves as the neural network's doorway.It's a way to provide a machine learning system some initial numerical data.A cube matrix may be used for an RGB image, whereas a square array may be used for a monochrome image, depending on the type of input data.
Hidden Layers
All the magic happens here.Convolution, pooling, normalizing, and activation are all components of the CNN's hidden layers.Let's take a closer look at how the picture recognition system works layer by layer.
Сonvolutional Layer
As stated previously, the CNN differs from traditional architecture with completely connected layers where each value is fed to each neuron in the layer.Instead, CNN uses trainable filters to create feature maps.This is a 2D or 3D matrices with trainable weights.
Applied to the input matrix.Adding up their values yields one number.The filter then “steps,” flipping by a stride length value, and continues multiplication.The output is a 2D matrices of the same size or less called a feature map.
Batch Normalization
Normalization usually occurs before activation.A math function with two trainable parameters: expectation and variance.Its job is to normalize and equalize numbers in a range suitable for activation.Normalization reduces training time and improves performance.It also allows customizing each layer independently, with minimum impact on others.
Activation Function
This is a barrier that doesn't pass certain values.Several arithmetic functions are employed in computer vision algorithms.However, the most common approach for picture recognition is rectified linear unit activation (ReLU).If an array element is negative, this function replaces it with 0.
Pooling Layer
No neural network training here.This layer reduces the size of the input layer by selecting the maximum or average value inside a kernel's area.In the absence of the pooling layer, the output and input will be the same dimension, increasing the number of changeable parameters, requiring more computer processing, and decreasing the algorithm's overall efficiency.
Output Layer
This layer contains neurons that represent the algorithm's classifications.The softmax function corrects output values so that their sum equals 1.The network's answer will be the largest value, which is the input picture class.
What Is The Difference Between Object Detection And Image Recognition?
Image Classification helps us classify images.Object Detection locates many things in a picture whereas Image Detection locates a single object.
Conclusion
You may automate company procedures and hence increase productivity by using an image recognition system.An image element can be recognized by a model and programmed to perform a certain action.Several use cases are now in production and widely deployed across industries and sectors.
In the telecommunications industry, for example, quality control automation was used.In reality, field technicians employ image recognition to inspect their work.
Another example is a smart video surveillance system that can detect strange behavior or situations in parking lots.
Image recognition can thus be used in telecommunications, video surveillance, construction, and pharmaceuticals.